

A mediados de diciembre hablamos sobre Riffusion, una variante de Stable Diffusion que nos permite crear música con inteligencia artificial, a partir de un simple texto. El tiempo está a favor de los algoritmos, y con cada nuevo proyecto obtenemos resultados más precisos. Hoy es el turno de Google Research, que acaba de presentar a MusicLM. Además de crear audio en 24 KHz, este modelo soporta condiciones especiales como la generación de melodías largas, y un «modo historia» para preparar secuencias.
La explosión viral de ChatGPT provocó un «código rojo» en Google. El gigante de Mountain View utiliza inteligencia artificial en varios niveles, pero todo parece indicar que se aproxima una ola de nuevos proyectos como respuesta directa al chatbot de OpenAI. Dicho de otra forma, Google necesita enseñar al público sus cartas un poco más, y una de ellas es MusicLM. Este trabajo de Google Research nos propone algo muy interesante: Generar música con inteligencia artificial, usando una simple descripción.
MusicLM: ¿Cómo suena la música hecha con inteligencia artificial?
La página de demostración no posee un modelo activo de MusicLM, pero está repleta de ejemplos acompañados por sus respectivos prompts. El entrenamiento de MusicLM se basa en «un gran dataset de música sin etiquetas», y en otro dataset llamado MusicCaps, con un total de 5.521 combinaciones de música y texto. Las descripciones de MusicCaps fueron creadas por humanos, y el audio asociado proviene de AudioSet, una colección con más de dos millones de clips de audio (diez segundos de duración), extraídos de YouTube.
«The main soundtrack of an arcade game. It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds, like cymbal crashes or drum rolls.»
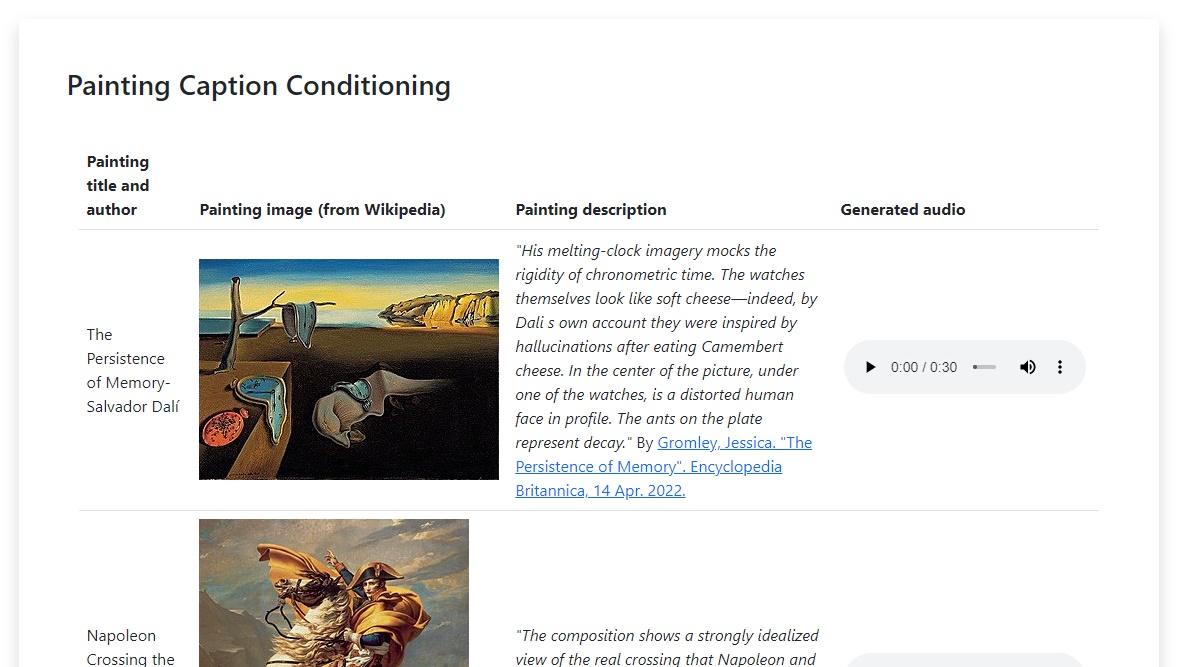
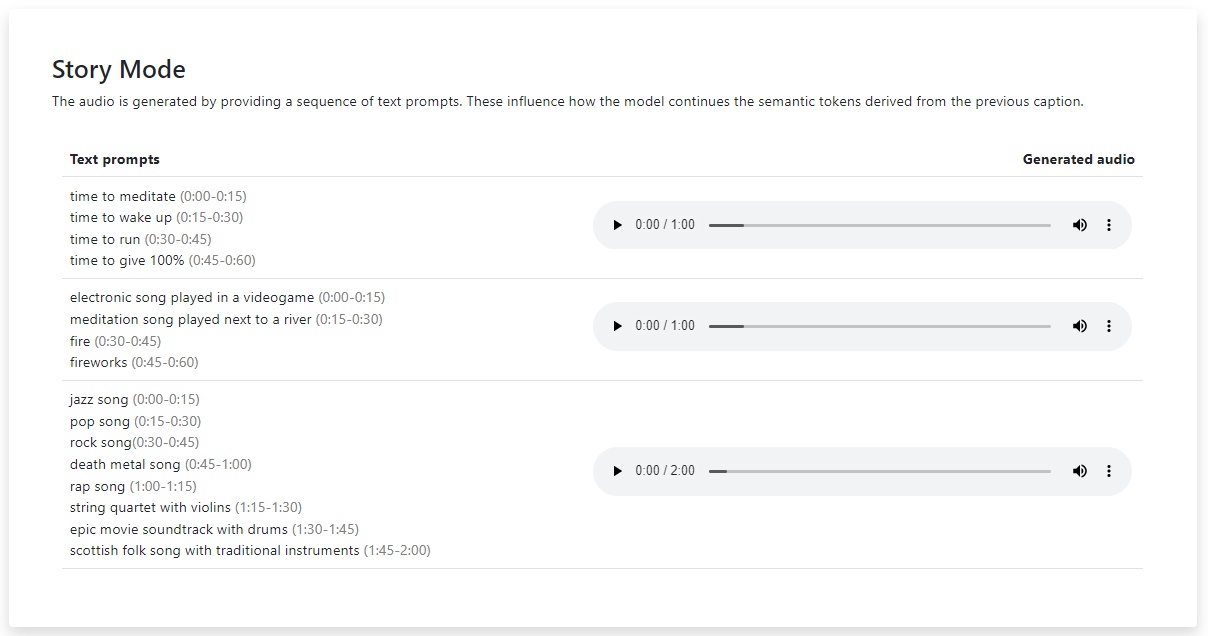
Los resultados de MusicLM están divididos en varias categorías. La primera de ellas es «Rich Captions», con muestras de 30 segundos basadas en una breve descripción. «Long Generation» nos enseña el potencial del modelos para crear canciones completas con una duración de cinco minutos. «Story Mode» convierte a las descripciones en secuencias con intervalos definidos, «Text and Melody Conditioning» combina el texto del prompt con una melodía de referencia, y «Painting Caption Conditioning» genera audio inspirado en una pintura o imagen.
A eso se suma la capacidad de MusicLM para reproducir instrumentos y géneros específicos, niveles de experiencia musical (un pianista novato o un maestro violinista), lugares, épocas, y más. Sin embargo, todo lo que tenemos hasta aquí son sus ejemplos oficiales. Google Research confirmó que «no hay planes» para compartir modelos por ahora, y tienen muchos desafíos por delante (hipotéticos problemas de copyright, sesgo cultural, etc.).
Sitio oficial: Haz clic aquí
