


En nuestro artículo sobre los mejores generadores de imágenes con inteligencia artificial reconocemos que los entornos locales no son para todo el mundo… pero es imposible negar su superioridad. La ausencia de límites y la posibilidad de utilizar múltiples modelos cambian las reglas por completo, sin embargo, nada de eso nos sirve sin una buena interfaz. Así llegamos a ComfyUI, que se inspira en diseños modulares y diagramas de flujo para brindar una experiencia mucho más intuitiva.
Disolviendo límites
Los servicios gratuitos que hemos compartido recientemente funcionan muy bien, y son un excelente punto de partida para cualquier usuario que desee generar imágenes sin descargar nada. Pero el objetivo final de todos ellos es que el dinero cambie de manos, y para lograrlo no hacen más que imponer una serie de límites, entre los que se destacan el número diario de tokens, la disponibilidad de modelos, y por supuesto, el tipo de imágenes que podemos generar.
Los modelos offline basados en Stable Diffusion arrancan todo eso de raíz. Una vez que superamos la dificultad principal (una tarjeta gráfica Nvidia que no se quede atrás en materia de VRAM), se abre un amplio abanico de posibilidades con modelos alternativos, alta resolución, inpainting, upscaling, cruce de modelos, y mucho más. Ahora, la recomendación número uno para estos casos es Automatic1111 (que incluye mejor soporte en GPUs AMD e Intel), pero también existe ComfyUI, y eso es lo que vamos a explorar hoy.
Cómo instalar ComfyUI para generar imágenes con Stable Diffusion offline
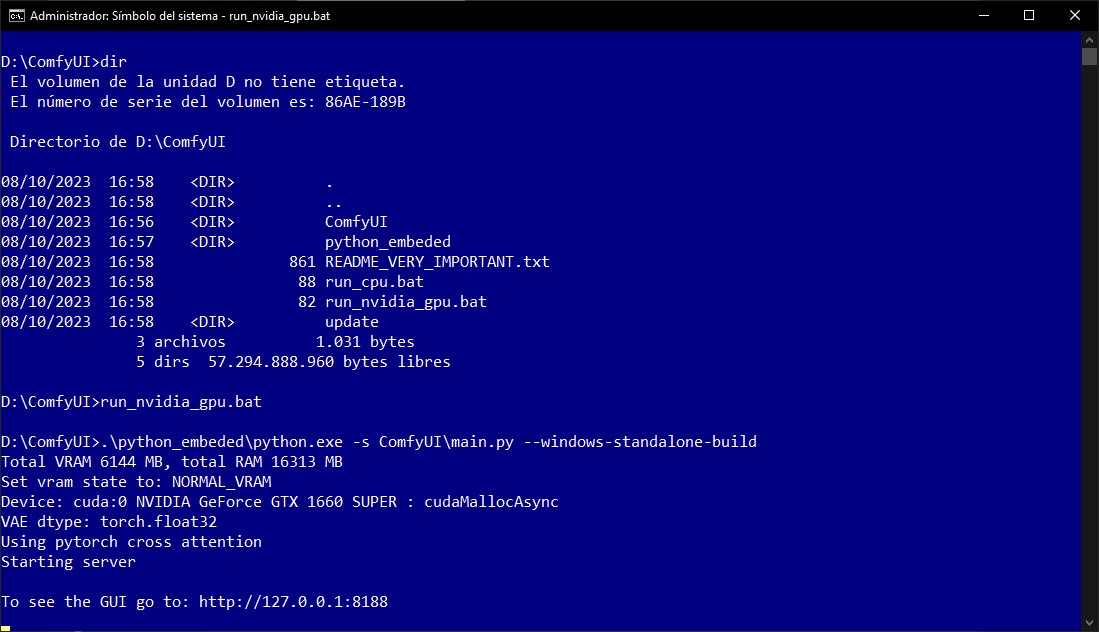
Uno de los aspectos más positivos de ComfyUI es que ya viene listo para usar en un archivo .7z de 1.4 gigabytes. Todas sus dependencias están incluidas, y lo único que debemos hacer (además de descomprimir su contenido) es ejecutar el archivo run_nvidia_gpu.bat o run_cpu.bat (esto habilita el uso del CPU, pero funcionará muy lento) desde una consola de sistema con privilegios elevados.
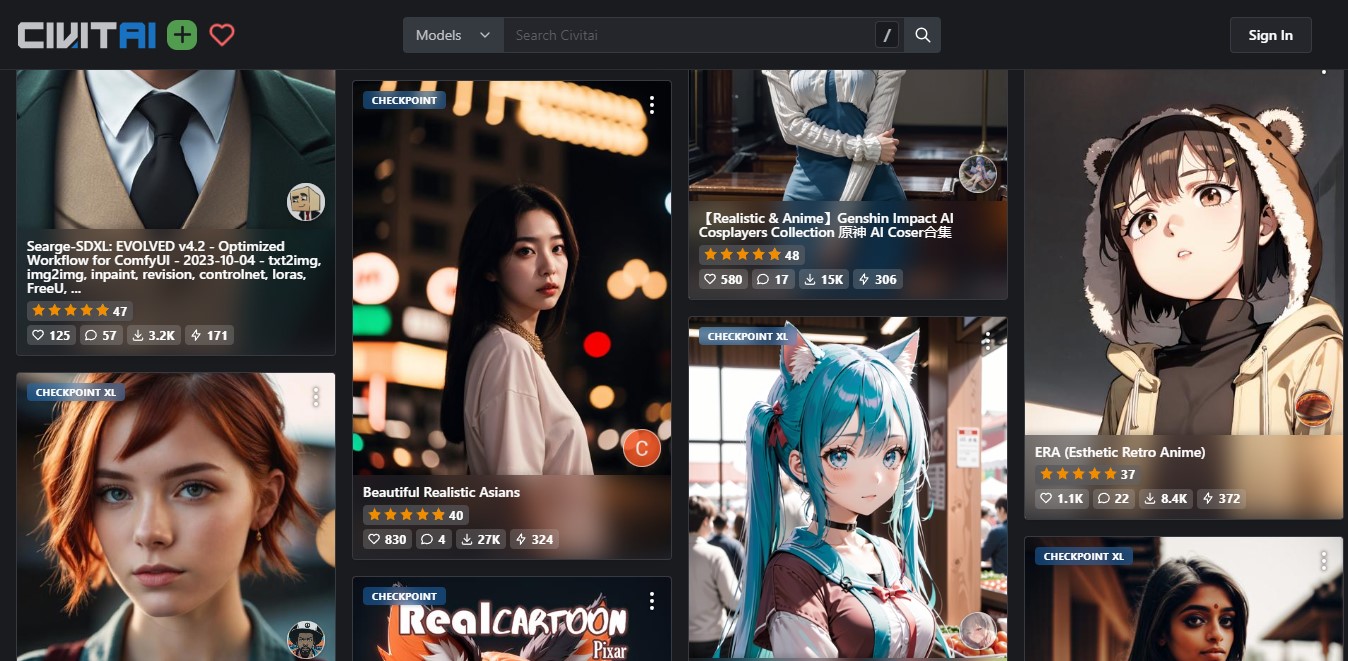
Pero antes de llegar a ese punto, necesitamos descargar algún modelo compatible. ComfyUI funciona con todas las versiones de Stable Diffusion, sin embargo, la mejor sugerencia es visitar Civitai, buscar un modelo que llame la atención, y descargarlo. La cantidad de material NSFW es muy importante allí, y no es buena idea usar un equipo público o de trabajo. Los modelos oscilan entre 1.5 y 6.5 gigabytes, y se guardan dentro de la subcarpeta ComfyUI\models\checkpoints. No importa si son «Checkpoints» o «SafeTensors» (recomendado), ambos funcionan del mismo modo.
Usando ComfyUI por primera vez
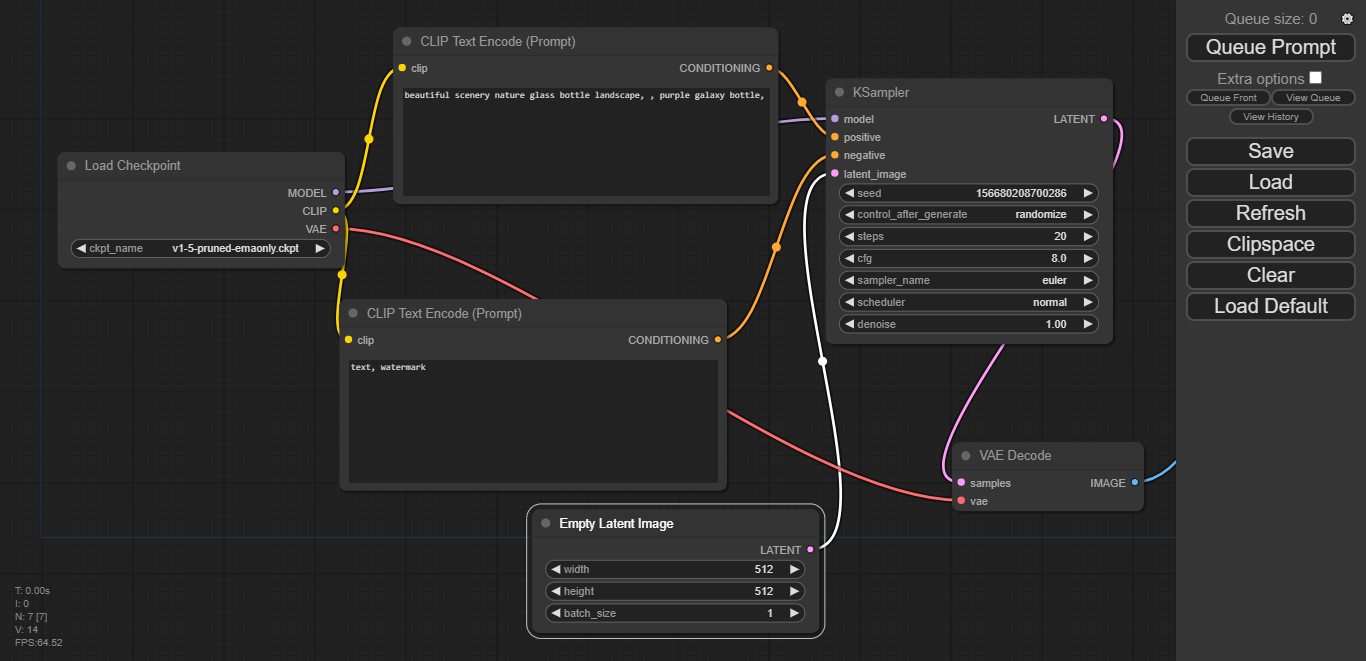
Con el contenido descomprimido y nuestro modelo almacenado en la subcarpeta correcta, es hora de abrir run_nvidia_gpu.bat. Si todo sale bien, esto creará una pestaña en el navegador predeterminado con la dirección http://127.0.0.1:8188/, presentando así la interfaz de ComfyUI.
No hay de qué preocuparse. Parece diseñada por un extraterrestre, pero tiene mucha lógica. Esta configuración estándar habilita todo lo que necesitamos para generar imágenes casi de inmediato, y apenas requiere un puñado de ajustes.
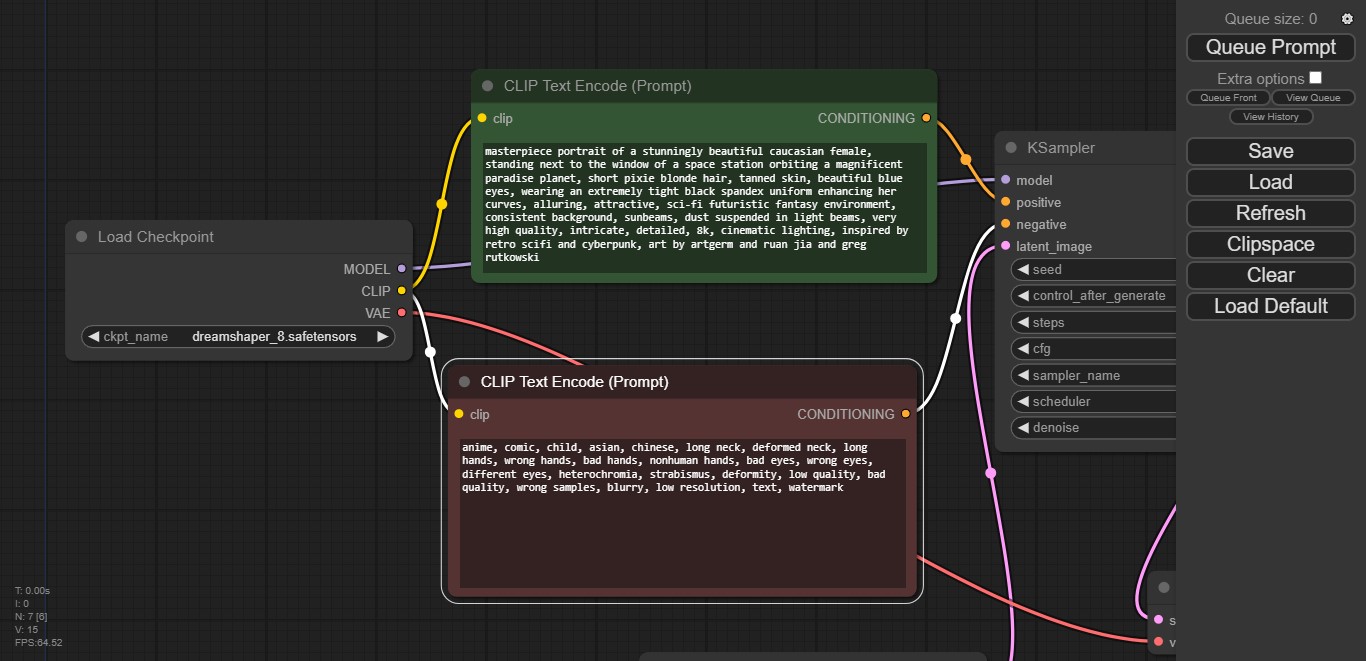
- El módulo Load Checkpoint nos permite seleccionar los modelos instalados. Aquí debemos hacer clic en las flechas hasta que aparezca el nombre del modelo que obtuvimos en Civitai. Los tres puntos con sus enlaces, identificados como Model, CLIP y VAE, se mantienen intactos.
- En este ejemplo, hay dos módulos llamados CLIP Text Encode, y son idénticos salvo por un detalle esencial: Uno posee condición positiva (o sea, «lo que queremos ver» en la imagen), y el otro condición negativa («lo que no queremos ver»). Aquí cargamos los prompts, y los enlaces de Conditioning van a Positive y Negative respectivamente.
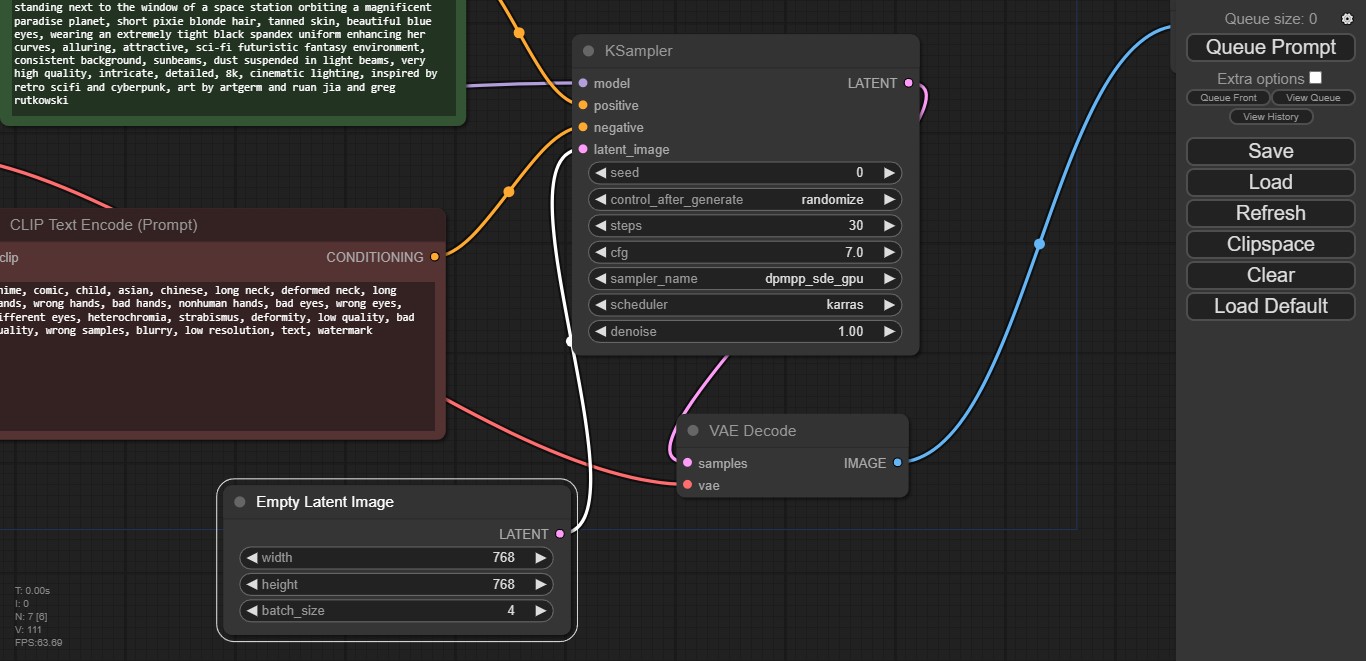
- El módulo Empty Latent Image no hace más que establecer la resolución final de las imágenes, y qué tan grande debe ser el lote. Si elegimos valores muy altos en ambos campos, aumenta el riesgo de saturar la VRAM disponible. Hay que experimentar.
- Lo mismo se aplica al módulo llamado KSampler. La magia sucede aquí: KSampler habilita control de seed y cómo debe ser procesada (randomize es lo ideal), el número de pasos, guidance o intensidad (CFG), sampler, scheduler, y nivel de denoise. En lo personal prefiero aumentar los pasos a 30, y bajar el CFG a 7. La combinación euler/normal es adecuada para comenzar, y el denoise debería quedar en 1.00 con nuevas generaciones.
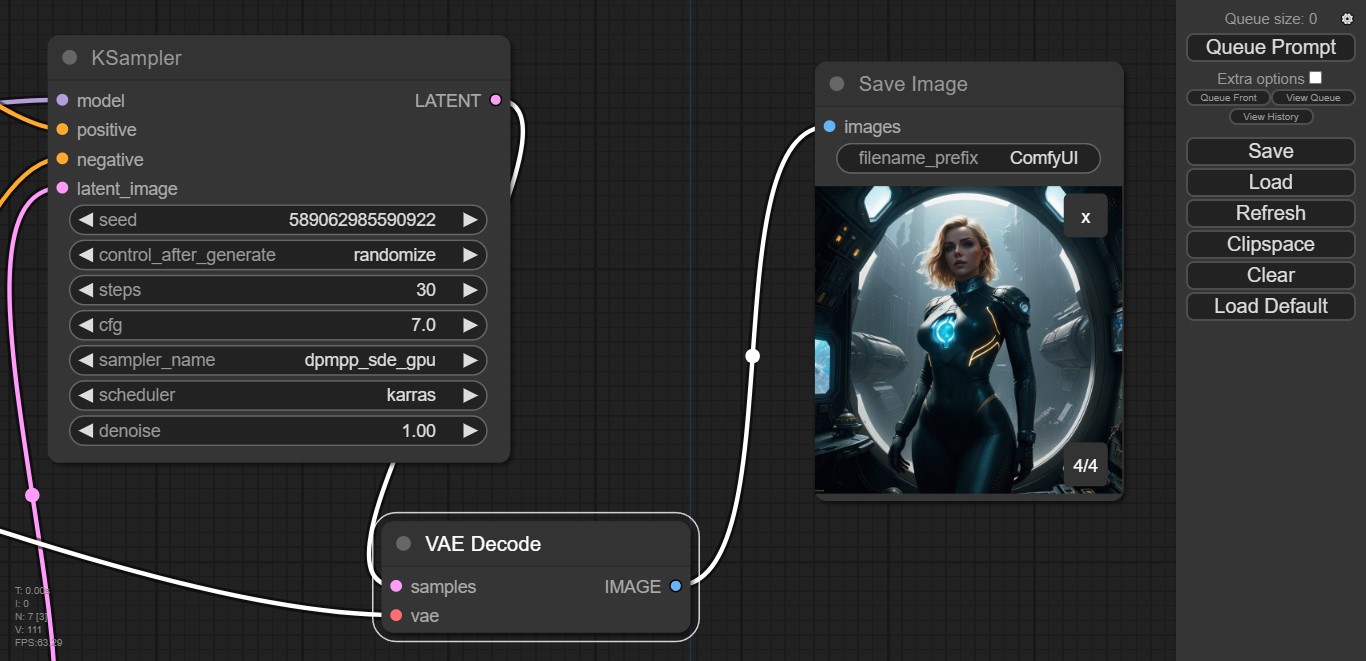
- Los últimos dos módulos son VAE Decode, que transforma el caos latente en imágenes reales (no necesita intervención del usuario), y Save Image, que guarda automáticamente todos los resultados en la carpeta ComfyUI/output, y los presenta en una mini galería. Un clic en Queue Prompt iniciará la generación.
«Ad infinitum»
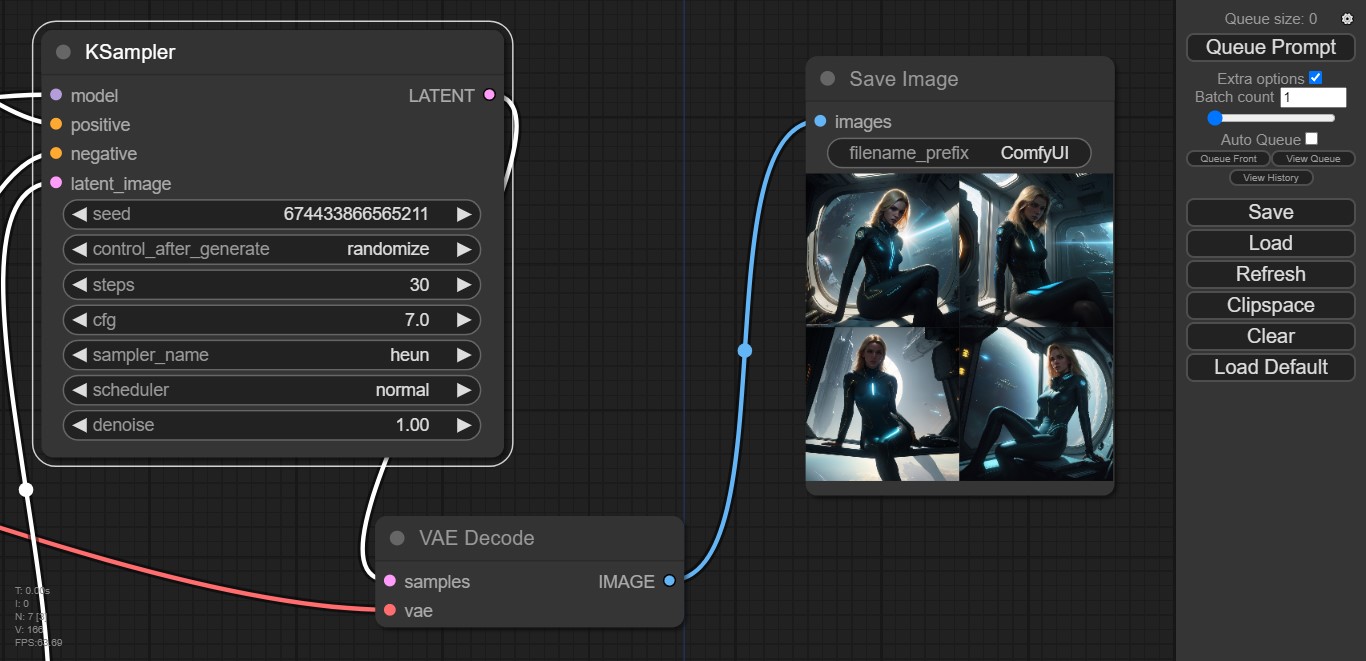
¿Las imágenes no son buenas? Sólo hay que intentarlo de nuevo, y de nuevo, y de nuevo… todas las veces que sea necesario. La libertad frente a los tokens nos permite hacer esto hasta el aburrimiento, probar nuevos modelos, incorporar LoRAs, embeddings e inversiones textuales… pero esa es otra historia.
El punto es que con ComfyUI, los errores no tienen costo, no hay tokens para quemar. Apenas hemos explorado la superficie de esta interfaz, y la comunidad ya ofrece docenas de módulos adicionales, pero en su configuración por default, ComfyUI brinda una sólida plataforma para generar imágenes con inteligencia artificial offline, y creo que todos los que posean el hardware apropiado deberían hacer la prueba.
Sitio oficial y descarga: Haz clic aquí
