
La generación de imágenes con inteligencia artificial y texto ha puesto a la Web de cabeza. En las últimas semanas hemos visto de todo, desde buscadores dedicados hasta primeros premios en concursos de arte. Sin embargo, también es necesario explorar la zona gris detrás de los generadores: Millones de ilustraciones, pinturas y fotografías que fueron recolectadas sin el permiso o la autorización correspondiente. El portal Have I Been Trained busca asistir a usuarios y artistas por igual para localizar sus trabajos y fotografías dentro de los modelos de entrenamiento, y en lo posible, solicitar su retiro.
«Nanos gigantum humeris insidentes». En su versión más moderna, estar de pie sobre los hombros de gigantes. La frase apunta al hallazgo de verdades inspiradas en trabajos y descubrimientos previos, pero podemos aplicarla a muchas otras cosas, incluyendo a las inteligencias artificiales. Un algoritmo es tan bueno como su entrenamiento, y si nos concentramos en proyectos al nivel de DALL-E 2, Stable Diffusion y Midjourney, dicho entrenamiento se basa en miles de millones de imágenes… hechas por alguien más.
Por supuesto, con las imágenes no es suficiente: Los metadatos son fundamentales para que el mecanismo de prompts no arroje resultados absurdos, pero el debate ético que tenemos por delante es inmenso, especialmente con Midjourney y Stable Diffusion vendiendo «créditos» para el uso de sus versiones online. La propuesta de Mat Dryhurst, Holly Herndon, Jordan Meyer y P_Hoep es darle a los artistas una opción con la herramienta Have I Been Trained?.
Have I Been Trained? Localiza tu arte en modelos de entrenamiento para IA
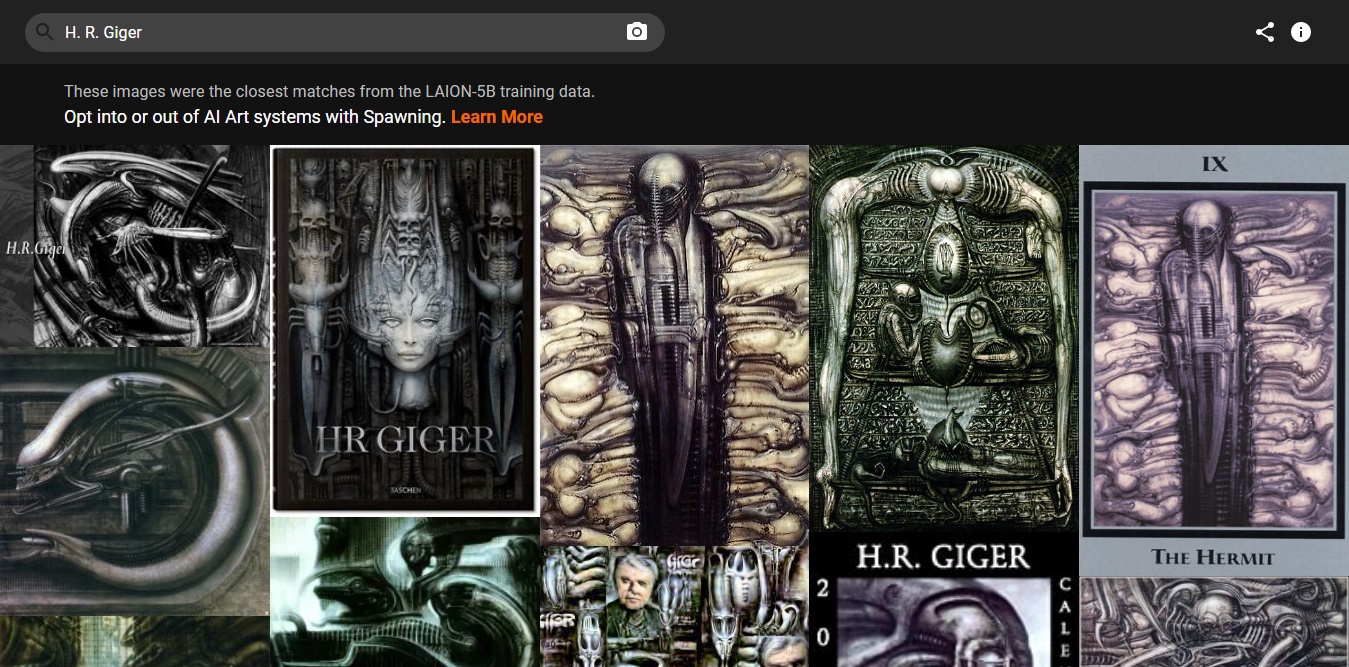
Básicamente, la idea es que los artistas puedan ingresar parámetros específicos o realizar una búsqueda inversa cargando imágenes para detectar si su trabajo forma parte del set LAION-5B. Al mismo tiempo, los usuarios pueden realizar la misma búsqueda aplicada a fotos o trabajos personales que hayan sido compartidos en diferentes plataformas.
Si el resultado es positivo, el siguiente paso es unirse al proyecto Spawning, actualmente en versión beta, para desarrollar un estándar que habilite a los artistas la posibilidad de definir un opt-in / opt-out en los modelos de entrenamiento, especificar permisos o límites a la hora de adoptar su estilo, y ofrecer sus propios modelos al público.
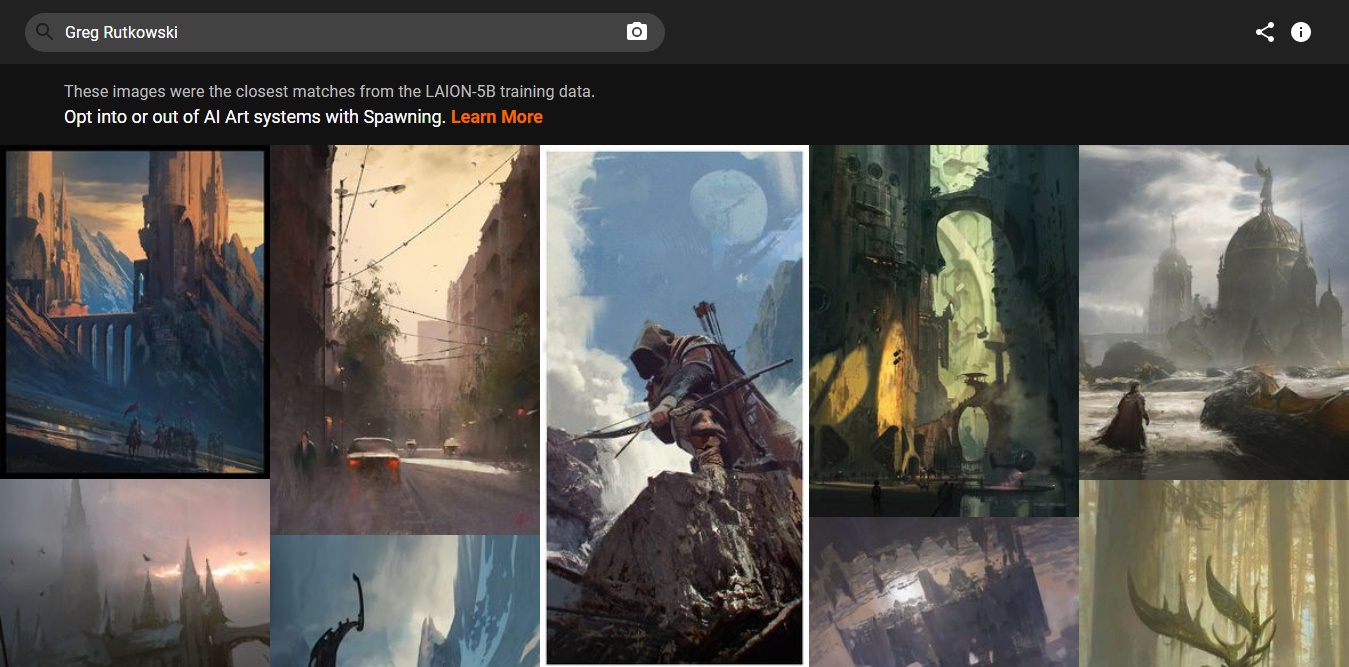
¿Qué tan bien funcionará esto? Honestamente no lo sabemos, pero una cosa es segura: La recolección de material público continuará. El concepto de scraping es legal en los Estados Unidos (por ahora), y las leyes de copyright alrededor del mundo poseen artículos enteros dedicados a «obras derivadas». Cualquier herramienta que ayude a resolver conflictos es bienvenida, y esperamos que tanto Have I Been Trained? como Spawning sigan avanzando.
(N. del R.: El sitio usa filtros NSFW, pero no logra bloquear todo. Ten cuidado.)
Sitio oficial: Haz clic aquí